 꿀팁 블로그
꿀팁 블로그
반응형

파이썬 에서 데이터를 쉽게 다룰 수 있는 라이브러리
- 2차원 형태의 데이터를 집계하거나 전처리 등을 아주 쉽게 할 수있음
- 정형 데이터를 다루기 위한 라이브러리
- Series(여러개면 DataFrame이 된다.)
- 2차원 구조로 되어있는 행렬 데이터
- DataFrame
- 2차원 구조로 되어있는 행렬 데이터
- Series(여러개면 DataFrame이 된다.)
import numpy as np
import pandas as pddata = [
["A군",30,170],
["B군",25,180]
]
df = pd.DataFrame( data, columns =["이름", "나이", "키"] )
df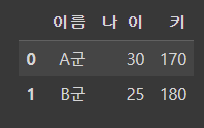
df["이름"]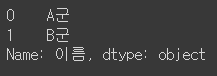
df["나 이"] # 단어에공백이 있으면 이런식으로 해야됨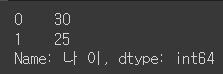
arr = np.load("samsung_stock_2021.npy") # 주식 데이터, 데이터 필요함
columns = ["시작가","상한가","하한가","종가"]
pd.DataFrame(arr,columns=columns)
data = {
"이름" : ["A군","B군","C군"],
"나이" : [35,33,28],
"키" : [180.1,175.5,170.0]
}
pd.DataFrame(data)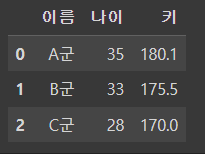
DATA_PATH = (f'/content/drive/MyDrive/01-python/data/db.yaml/') # 경로에 데이터 있어야함!pip install pymysql
import yaml
DB_INFO =f"/content/drive/MyDrive/01-python/data/db.yaml"
with open(DB_INFO,'r') as f:
db_info = yaml.load(f,Loader=yaml.Loder)
db_infoimport yaml
DB_INFO ="/content/drive/MyDrive/01-python/data/db.yaml"
with open(DB_INFO,"r") as f:
db_info = yaml.load(f,Loader=yaml.Loader)import pymysql
conn = pymysql.connect(
user = db_info["USER"],
passwd = db_info["PASSWD"],
host = db_info["HOST"],
port = 3306,
db = "playdata",
)
conn<pymysql.connections.Connection at 0x7f02f96d31d0>
sql 이용 데이터프레임
df = pd.read_sql("select * from titanic_raw",conn)
df
- 저장
df.to_csv(f"{DATA_PATH}파일이름.csv",index = False)- 불러오기
df = pd.read_csv(f"파일경로.csv")
df
DataFrame 정보 확인하기
df.columns
df.info(verbose=True,null_counts=True) # 모든정보를 보고싶을때verbose=True null_counts=True 널값볼때
수치형 컬럼에 대한 요약 통계 보기
df.describe()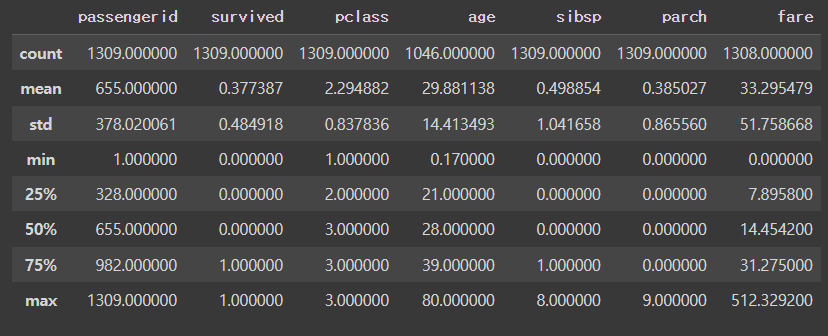
df.shape
( 1390, 12 )df.head(40) # 위에서 40개 끊음
df.tail() # 밑에서부터데이터 프레임 다루기
- copy메소드
- 데이터프레임을 복사한다.
- 기본적으로 깊은복사
df_cp = df.copy()
df_cp.head()
컬럼명 변경하기
한번에 변경하기
cols = df_cp.columns.tolist()
cols[0] = "pid"
cols
df_cp.columns = cols
df_cp.head()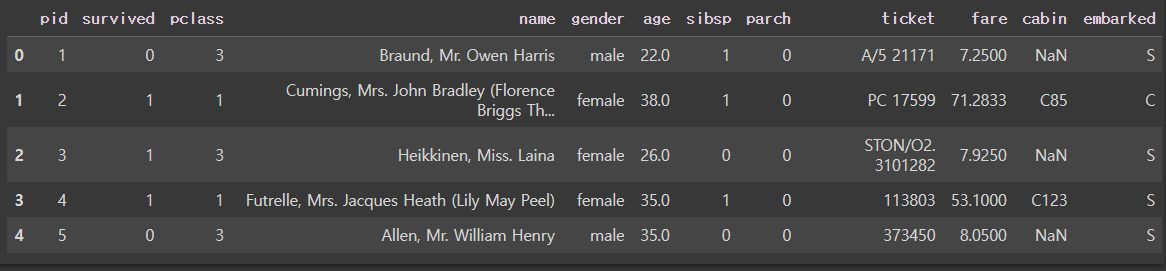
컬럼명 변경
# 새로운 컬럼을 생성하며 변경
cols_rename = {
"survived" : "target"
}
df = df.rename( columns = cols_rename)# 컬럼 자체를 변경, 권장하지 않음
df_cp.rename( columns = { "survived" : "target" }, inplace = True )

- add_prefix
df.add_prefix("엿_")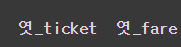
- sdd_suffix
df.add_suffix("_엥")
- 특정 컬럼만 선택
cols = [ "name", "gender", "age" ]
df[cols]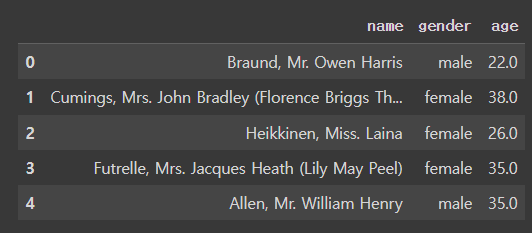
컬럼삭제
- drop 메소드
- axis = 0 : 행 , 1 : 열
df.drop( "name", axis = 1 )- 직관적인 방법
df.drop( columns = [ "name", "age" ] )- 내림차순 정렬
df.sort_values( by = "age", ascending = False ) # True : 오름차순데이터 프레임 섞기
from pandas.core.common import random_state
df2 = df.sample( frac = 1, random_state = 42 ) #random_state 시드값 키워드 frac=0.2 비율을 정할수있음 1이 백프로iloc
- 행번호와 열번호를 이용한 행렬 슬라이싱
df2.iloc[:5,1:5] # 0:5행,1:5열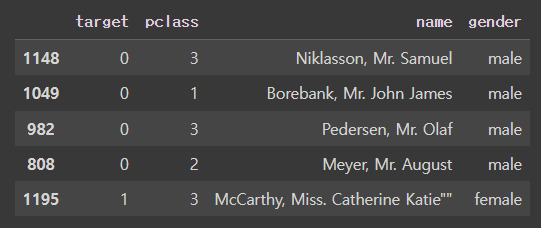
num_rows = [1,3,5]
num_cols = [0,4,2]
df2.iloc[num_rows,num_cols]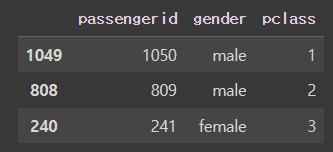
loc
- index 명과 columns 명을 이용한 슬라이싱
- 마스킹을 이용해서 행과 열을 선택이 가능하다.
df.loc[3] # 일반슬라이싱과 다르게 앤드 번호로 나옴
df.loc[:,["embarked","age","fare"]]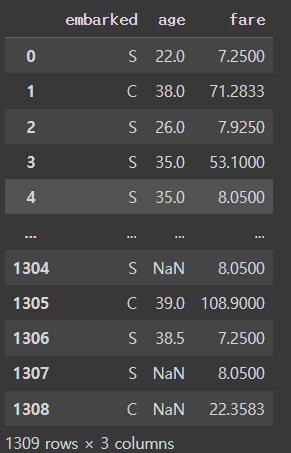
idx = [1,2,3]
cols=["name","age","embarked"]
df.loc[idx,cols]
마스킹을 이용한 방법
- loc 를 사용해야한다.
mark = df2["target"] == 1 # 생존자만 찾기
df2.loc[mark]
mask1 = df2["target"] ==1
mask2 = df2["age"] <20
df2.loc[mask1 &mask2].head()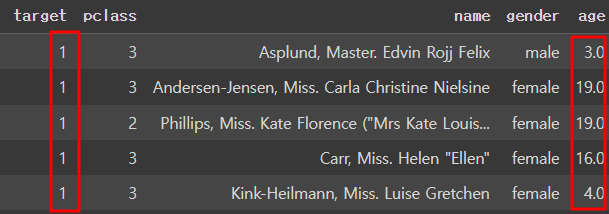
컬럼 추가하기
data = [
["A군",30,170],
["B군",25,180],
["C군",30,175]
]
df_info = pd.DataFrame(data,columns=["이름" ,"나 이","키"])
df_info
cols =["주소","전화번호"]
rows =[
["강남","010-1111-1111"],
["강북","010-2222-2222"],
["강동","010-3333-3333"]
]
df_info[cols] = rows
df_info
Nan 값
df_info["전화번호"] = np.nan
df_info
df_info.loc[1,"전화번호"] = "010-2222-2222"
df_info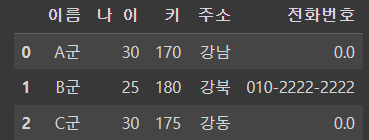
반응형
'python' 카테고리의 다른 글
| [python]파이썬 - numpy (0) | 2023.02.10 |
|---|---|
| [pypthon]파이썬 - pandas 를 이용한 eda (0) | 2023.02.02 |
| [python]파이썬 - open API (2) | 2023.01.30 |
| [python]파이썬 - pip와 가상환경 (0) | 2023.01.26 |
| [python]파이썬 - 파일 입출력 (0) | 2023.01.26 |




댓글