 꿀팁 블로그
꿀팁 블로그
반응형

Open API 란?
- API(application programming interface)는 프로그램의 특정한 부분에 요청해서 그 안에 있는 데이터와 서비스(기능)를 이용할 수 있게 해주는 소프트웨어 인터페이스
- 다양한 데이터를 어디서나 쉽게 이용할 수 있도록 개방된 API
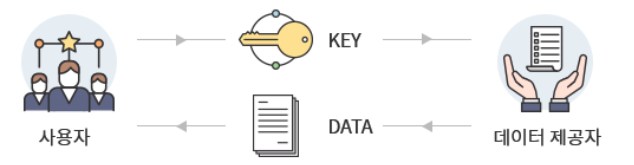
주요 Open API 제공처
- 공공데이터포털 (http://www.data.go.kr/)
- 네이버 Developers 센터 (http://developers.naver.com/)
- 구글 디벨로퍼 (http://developers.google.com/)
- 페이스북 for 디벨로퍼 (http://developers.facebook.com/)
- 카카오톡 디펠로터 ((http://developers.kakao.com/)
HTTP(Hyper Text Transfer Protocol) 란?
- HTML, Plain text, JSON, XML , 이미지 , 동영상 등 다양한 형태의 정보도 전송하는 프로토콜
- HTTP의 동작 방식
HTTP 통신 방식
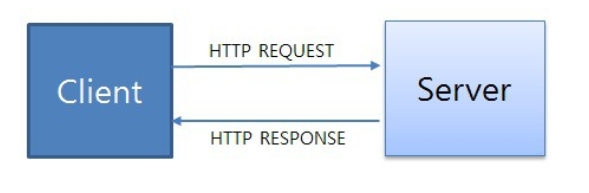
HTTP Packet
- HTTP 통신으로 서버와 클라이언트 사이에 주고 받는 데이터를 말한다.
- Request Header
- 클라이언트가 서버에 요청할 때 존재하는 헤더로 요청한 URL, Method, 브라우저 정보 등이 포함되어 있다.
- Respone Header
- 서버가 클라이언트의 요청에 대한 응답을 할 때 존재하는 헤더로 콘텐츠에 사용된 인코딩, 응답을 생성하기 위해 서버 시스템에서 사용되는 서버 소프트웨어 및 기타 정보 등이 포함되어 있다.
- HTTP Body
- 서버에서 응답시 클라이언트가 요청한 실제 데이터가 포함되어 있다.
- HTML , image, css , javascript, text ...
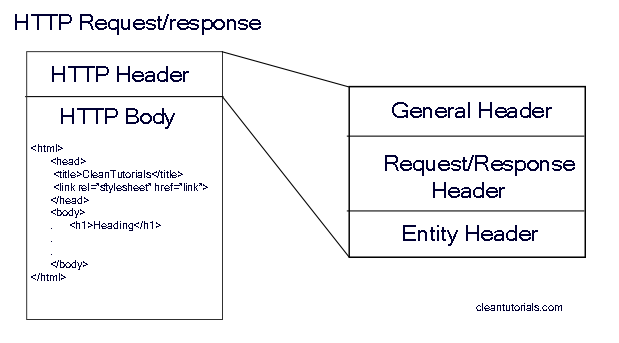
HTTP 메소드 와 상태코드
- HTTP 메소드란?
- 서버에 요청을 보내는 방식
- GET 방식 : URL 에 데이터를 담아 요청
- POST 방식 : GET 방식과는 달리 body영역에 데이터를 담아 요청
- HTTP 상태 코드(응답)
- 클라이언트가 서버에 요청을 하면, 서버는 요청에 대한 처리 상태를 숫자로 반환하는데 이를 상태 코드라고 한다.
- 2xx: 요청성공(ex. 200)
- 3xx: 요청이 유효하지만 주소가 변경(ex. 301)
- 자동으로 변경된 주소로 이동
- 4xx: 클라이언트 오류(ex. 404)
- 5xx: 서버 오류(ex. 500)
- https://developer.mozilla.org/ko/docs/Web/HTTP/Status
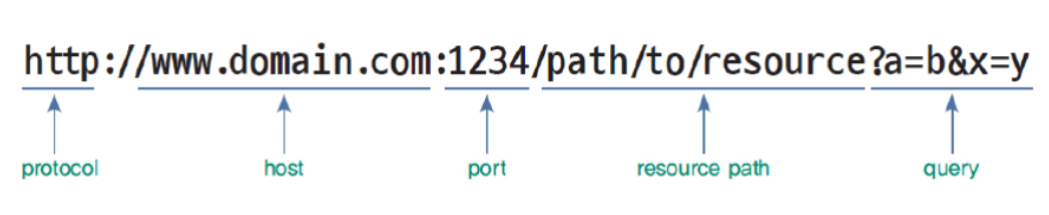
URL 구조
osi7
reqeusts 라이브러리
- http 요청을 보내 응답을 받을수 있다.
import requests
res = requests.get("http://naver.com") # 응답 객체가 반환된다
res.status_code
200res.encoding # 응답 컨텐츠에 대한 인코딩 정보
res.text
res.request.body # GET방식으로 보내서 BODY 영역에 아무것도 없다.
res.request.method # 요청 방식도 확인할수있다.
res.request.headers # 요청에 대한 헤더정보
{'User-Agent': 'python-requests/2.23.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}res.headers #응답에 대한 헤더정보
{'Server': 'NWS', 'Content-Type': 'text/html; charset=UTF-8', 'Cache-Control': 'no-cache, no-store, must-revalidate', 'Pragma': 'no-cache', 'P3P': 'CP="CAO DSP CURa ADMa TAIa PSAa OUR LAW STP PHY ONL UNI PUR FIN COM NAV INT DEM STA PRE"', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Strict-Transport-Security': 'max-age=63072000; includeSubdomains', 'Referrer-Policy': 'unsafe-url', 'Content-Encoding': 'gzip', 'Date': 'Thu, 18 Aug 2022 00:49:34 GMT', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive, Transfer-Encoding', 'Vary': 'Accept-Encoding'}URL 인코딩
- 퍼센트(%) 인코딩 이라고도 함
- 영문자와 숫자와 일부 특수문자에 대한 URL에서 사용할수 없는 한글이나 특수문자 들을 인코딩 한다.
- 디코딩 되어있는 서비스키를 사용할 경우
ServiceKey = "gJptcVA42L1/xrflQMnIi5HocBdBgojtF+W2Gq+X0Rp/IUltNk1zrz39E2pVvyzX+s7u2cqprEkcVPWbd4UggQ=="
returnType = "xml"
startDate = "2022-01"
endDate = "2022-01"
url = "http://apis.data.go.kr/B553734/iseelectricprod/getElectricProduction"
query = f"?ServiceKey={ServiceKey}&returnType={returnType}&startDate={startDate}&endDate={endDate}"
url+query
res = requests.get(url+query)
res.status_code
200res.text
- 인코딩 하기
ServiceKey = "gJptcVA42L1/xrflQMnIi5HocBdBgojtF+W2Gq+X0Rp/IUltNk1zrz39E2pVvyzX+s7u2cqprEkcVPWbd4UggQ=="
ServiceKey = requests.utils.quote(ServiceKey)
ServiceKey
- 디코딩하기
requests.utils.unquote(ServiceKey)
returnType = "xml"
startDate = "2022-01"
endDate = "2022-01"
url = "http://apis.data.go.kr/B553734/iseelectricprod/getElectricProduction"
query = f"?ServiceKey={ServiceKey}&returnType={returnType}&startDate={startDate}&endDate={endDate}"
res = requests.get(url+query)
res.status_code
200res.text
- xml 을 딕셔너리로 변환해보기
!pip install xmltodict
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting xmltodict
Downloading xmltodict-0.13.0-py2.py3-none-any.whl (10.0 kB)
Installing collected packages: xmltodict
Successfully installed xmltodict-0.13.0
import xmltodict
dict_data = xmltodict.parse(res.text)
dict_data
{'response': {'header': {'resultCode': '00',
'description': '서울에너지공사 발전소 월별 전기생산량(발전량)',
'resultMsg': 'NORMAL CODE'},
'body': {'pageNo': '1',
'totalCount': '2',
'items': {'item': [{'unit': 'kWh',
'elecprodqty': '12911900.00',
'dates': '2022-01',
'branchNm': '동부지사',
'branchCd': '2'},
{'unit': 'kWh',
'elecprodqty': '8964872.00',
'dates': '2022-01',
'branchNm': '서부지사',
'branchCd': '1'}]},
'numOfRows': '10'}}}print(dict_data)
{'response': {'header': {'resultCode': '00', 'description': '서울에너지공사 발전소 월별 전기생산량(발전량)', 'resultMsg': 'NORMAL CODE'}, 'body': {'pageNo': '1', 'totalCount': '2', 'items': {'item': [{'unit': 'kWh', 'elecprodqty': '12911900.00', 'dates': '2022-01', 'branchNm': '동부지사', 'branchCd': '2'}, {'unit': 'kWh', 'elecprodqty': '8964872.00', 'dates': '2022-01', 'branchNm': '서부지사', 'branchCd': '1'}]}, 'numOfRows': '10'}}}
import pprint as pp
dict_data["response"]["body"]["items"][""]
data = res.json() # 딕셔너리 형태로 변환해서 반환한다.
type(data)
네이버 opne api 사용해보기
- 검색 api
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "kIVAXhyKBVqloyLnT9v7"
client_secret = "wZyet4gzXC"
encText = urllib.parse.quote("빅데이터와 인공지능")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
{
"lastBuildDate":"Thu, 18 Aug 2022 14:24:29 +0900",
"total":253321,
"start":1,
"display":10,
"items":[
{
"title":"<b>인공지능<\/b>, <b>빅데이터<\/b>특허 발명 보호를 위한 등록 방법",
"link":"https:\/\/blog.naver.com\/jninsa?Redirect=Log&logNo=222849778387",
"description":"저 역시 BM\/<b>인공지능<\/b>\/<b>빅데이터<\/b>\/플랫폼분야 등에서 전문변리사로 활동 중인 만큼, 문의해 주시는 내용을 직접 검토하여 피드백 드리고 있습니다. 출원 전 주의해야 할 부분이 있다면 실무적으로 봤을 때, 일반인이... ",
"bloggername":"윤 변리사의 실무 이야기",
"bloggerlink":"https:\/\/blog.naver.com\/jninsa",
"postdate":"20220816"
},
{
"title":"<b>빅데이터와 인공지능<\/b> : 세상을 바꾸는 기술 이야기",
"link":"https:\/\/blog.naver.com\/pareko?Redirect=Log&logNo=222609514030",
"description":"책 소개 이 책은 <b>빅데이터와 인공지능<\/b>을 주제로 생활변화에 대한 인문학 이야기 입니다. "호랑이는... 05 인공지능과의 동거 06 삐딱하게 바라본 기술의 진보 07 현실과 4차 산업의 괴리 08 진정한 4차... ",
"bloggername":"순돌아범",
"bloggerlink":"https:\/\/blog.naver.com\/pareko",
"postdate":"20211231"
},
{
"title":"<b>빅데이터<\/b>, <b>인공지능<\/b>, 플랫폼특허 등록 방법은?",
"link":"https:\/\/blog.naver.com\/llllllwish?Redirect=Log&logNo=222792337392",
"description":"오늘은 <b>빅데이터<\/b>, <b>인공지능<\/b>, 플랫폼 특허를 주제로 등록을 어떻게 진행해야 되는지에 대해서 말씀 드리려 합니다. 개인적으로 출원을 준비해서 등록까지 성공시킬 수 있는 확률은 불과 10%도 되지 않습니다.... ",
"bloggername":"98.3%, 테헤란",
"bloggerlink":"https:\/\/blog.naver.com\/llllllwish",
"postdate":"20220628"
},
{
"title":"대구 AI학원 <b>빅데이터<\/b> <b>인공지능<\/b> 결합교육까지",
"link":"https:\/\/blog.naver.com\/blogmania77?Redirect=Log&logNo=222777436807",
"description":"바로 이 방대해진 <b>데이터<\/b>들을 제대로 활용할 수 있도록 하는 직업이 오늘 설명드릴 <b>인공지능<\/b>·<b>빅데이터 과<\/b>정입니다. 대구 AI학원 또는 <b>빅데이터<\/b> 학원을 찾으시는 분들이라면 오늘 소개드릴 과정을... ",
"bloggername":"경북산업직업전문학교",
"bloggerlink":"https:\/\/blog.naver.com\/blogmania77",
"postdate":"20220617"
},
{
"title":"[<b>빅데이터<\/b> 트렌드] <b>빅데이터<\/b> <b>인공지능<\/b> 키워드 "빅블러"",
"link":"https:\/\/blog.naver.com\/theimc?Redirect=Log&logNo=222643714962",
"description":"빅데이터 키워드 빅블러(Big Blur)와 사례를 소개해드리겠습니다. 사물인터넷(loT), 핀테크, 인공지능(AI)... 또한 코로나19 팬데믹 확산으로 비대면 생활환경이 형성되면서 <b>빅데이터와 인공지능<\/b>은 계속하여... ",
"bloggername":"The IMC 더아이엠씨 : 마케팅에 빅데이터를 더하다",
"bloggerlink":"https:\/\/blog.naver.com\/theimc",
"postdate":"20220210"
},
{
"title":"4차산업혁명시대!, <b>빅데이터와 인공지능<\/b>",
"link":"https:\/\/blog.naver.com\/canal21?Redirect=Log&logNo=222606867355",
"description":"마치 내가 검색한 것을 모바일(정확히는 앱일까?)이 알고 보여주는 느낌이 들 정도여서 처음엔 무척 놀랐었는데 <b>빅데이터와 인공지능<\/b>으로 생각해보면 여러 종류의 데이터가 나도 모르는 사이에 모아지고... ",
"bloggername":"키미스의 사색공간, 꿈과 행복을 찾아서...♡",
"bloggerlink":"https:\/\/blog.naver.com\/canal21",
"postdate":"20211228"
},
{
"title":"솔트룩스 <b>인공지능<\/b> AI챗봇, <b>빅데이터<\/b> 기반 SW기업 소개",
"link":"https:\/\/blog.naver.com\/bk32167?Redirect=Log&logNo=222827482670",
"description":"솔트룩스는 <b>인공지능<\/b>, <b>데이터<\/b> 사이언스 국내 1위 기업입니다. 이미 많은 클라이언트들과 협업을 하고 있으며, 자연어처리, 시맨틱, 추론을 포함한 <b>인공지능<\/b> 분야의 독보적인 기술을 보유하고 있는 <b>데이터<\/b>... ",
"bloggername":"자유분방 IT사진",
"bloggerlink":"https:\/\/blog.naver.com\/bk32167",
"postdate":"20220728"
},
{
"title":"서강대 <b>빅데이터<\/b> 대학원 <b>데이터<\/b>사이언스 <b>인공지능<\/b>(ai) 학과... ",
"link":"https:\/\/blog.naver.com\/roseandme7753?Redirect=Log&logNo=222845224035",
"description":"<b>인공지능<\/b>, <b>빅데이터<\/b> 분석, 프로그래밍의 질문들이며 매년 면접 질문은 비슷해 준비하기 어렵진 않습니다. 서강대 <b>데이터<\/b> 분석 대학원 외 대표적인 대학원 알아보기 ※ 서강대 외 대표적인 <b>데이터<\/b>... ",
"bloggername":"인테리어",
"bloggerlink":"https:\/\/blog.naver.com\/roseandme7753",
"postdate":"20220810"
},
{
"title":"[<b>빅데이터<\/b>, <b>인공지능<\/b> 기술역량기반 디지털 전략 전문가... ",
"link":"https:\/\/blog.naver.com\/leelee3s?Redirect=Log&logNo=222844931565",
"description":"오늘 소개해드릴 교육내용은 <b>빅데이터와 인공지능<\/b>을 교육하는 과정인데요. 빅데이터 산업 활성화를... 국비전액지원 훈련과정명 빅데이터, 인공지능 기술역량기반 디지털 전략 전문가 양성과정 훈련기간 2022.... ",
"bloggername":"오! 해삐",
"bloggerlink":"https:\/\/blog.naver.com\/leelee3s",
"postdate":"20220810"
},
{
"title":"<인사이트 플랫폼> 디지털 플랫폼, <b>빅데이터와 인공지능<\/b>의 모든 것",
"link":"https:\/\/blog.naver.com\/indiecat?Redirect=Log&logNo=222120978879",
"description":"빅데이터 매뉴얼 <인사이트 플랫폼>. <b>빅데이터와 인공지능<\/b>이 가져올 사회의 변화에 대한 이야기는... 빅데이터, 인공지능, 네트워크 기술이 융합된 디지털 플랫폼에 대한 이해를 돕는 <인사이트 플랫폼>으로... ",
"bloggername":"인디캣책곳간",
"bloggerlink":"https:\/\/blog.naver.com\/indiecat",
"postdate":"20201020"
}
]
}
- 네이버 검색 api를 이용하여 영화 정보 받아오기
client_id ="kIVAXhyKBVqloyLnT9v7"
client_secret = "wZyet4gzXC"
headers ={
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
}
url = "https://openapi.naver.com/v1/search/movie.json" # 요청 URL만
params ={
"query":"완벽한 타인"
}
res = requests.get(url,params=params,headers=headers)
if res.status_code == 200:
data = res.json()
else:
print(f'Error Code:{res.status_code}')
print(data)
{'lastBuildDate': 'Thu, 18 Aug 2022 11:52:31 +0900', 'total': 5, 'start': 1, 'display': 5, 'items': [{'title': '<b>완벽한 타인</b>과의 섹스경험담', 'link': 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=207848', 'image': 'https://ssl.pstatic.net/imgmovie/mdi/mit110/2078/207848_P01_115152.jpg', 'subtitle': '', 'pubDate': '2021', 'director': '이로운|', 'actor': '', 'userRating': '0.00'}, {'title': '<b>완벽한 타인</b>: 블러디 문', 'link': 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=212261', 'image': 'https://ssl.pstatic.net/imgmovie/mdi/mit110/2122/212261_P01_170238.jpg', 'subtitle': 'Bloody Moon Fest', 'pubDate': '2020', 'director': '쿠앙 둥 뉴엔|', 'actor': '호 타이 화|안 홍|흐어 비 반|', 'userRating': '0.00'}, {'title': '<b>완벽한 타인</b> : 비밀의 스와핑', 'link': 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=188710', 'image': 'https://ssl.pstatic.net/imgmovie/mdi/mit110/1887/188710_P01_135128.jpg', 'subtitle': '', 'pubDate': '2019', 'director': '이지은|', 'actor': '', 'userRating': '0.00'}, {'title': '<b>완벽한 타인</b>', 'link': 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=167638', 'image': 'https://ssl.pstatic.net/imgmovie/mdi/mit110/1676/167638_P71_133542.jpg', 'subtitle': 'Intimate Strangers', 'pubDate': '2018', 'director': '이재규|', 'actor': '유해진|조진웅|이서진|염정아|김지수|송하윤|윤경호|', 'userRating': '8.61'}, {'title': '<b>완벽한 타인</b>: 킬 모바일', 'link': 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=184973', 'image': 'https://ssl.pstatic.net/imgmovie/mdi/mit110/1849/184973_P01_154931.jpg', 'subtitle': 'Kill Mobile', 'pubDate': '2017', 'director': '우묘|', 'actor': '통따웨이|마려|곽사연|교삼|톈위|대악악|해몽요|', 'userRating': '5.33'}]}
import pprint as pp
pp.pprint(data)
{'display': 3,
'items': [{'bloggerlink': 'https://blog.naver.com/jninsa',
'bloggername': '윤 변리사의 실무 이야기',
'description': '저 역시 BM/<b>인공지능</b>/<b>빅데이터</b>/플랫폼분야 등에서 전문변리사로 '
'활동 중인 만큼, 문의해 주시는 내용을 직접 검토하여 피드백 드리고 있습니다. 출원 전 '
'주의해야 할 부분이 있다면 실무적으로 봤을 때, 일반인이... ',
'link': 'https://blog.naver.com/jninsa?Redirect=Log&logNo=222849778387',
'postdate': '20220816',
'title': '<b>인공지능, 빅데이터</b>특허 발명 보호를 위한 등록 방법'},
{'bloggerlink': 'https://blog.naver.com/llllllwish',
'bloggername': '98.3%, 테헤란',
'description': '오늘은 <b>빅데이터</b>, <b>인공지능,</b> 플랫폼 특허를 주제로 등록을 어떻게 '
'진행해야 되는지에 대해서 말씀 드리려 합니다. 개인적으로 출원을 준비해서 등록까지 성공시킬 '
'수 있는 확률은 불과 10%도 되지 않습니다.... ',
'link': 'https://blog.naver.com/llllllwish?Redirect=Log&logNo=222792337392',
'postdate': '20220628',
'title': '<b>빅데이터</b>, <b>인공지능,</b> 플랫폼특허 등록 방법은?'},
{'bloggerlink': 'https://blog.naver.com/bk32167',
'bloggername': '자유분방 IT사진',
'description': '솔트룩스는 <b>인공지능,</b> <b>데이터</b> 사이언스 국내 1위 기업입니다. 이미 '
'많은 클라이언트들과 협업을 하고 있으며, 자연어처리, 시맨틱, 추론을 포함한 '
'<b>인공지능</b> 분야의 독보적인 기술을 보유하고 있는 <b>데이터</b>... ',
'link': 'https://blog.naver.com/bk32167?Redirect=Log&logNo=222827482670',
'postdate': '20220728',
'title': '솔트룩스 <b>인공지능</b> AI챗봇, <b>빅데이터</b> 기반 SW기업 소개'}],
'lastBuildDate': 'Thu, 18 Aug 2022 14:24:46 +0900',
'start': 1,
'total': 536024}
data["items"]
- 데이터 프레임으로 변환해보기
import pandas as pd
pd.DataFrame(data["items"])

client_id ="kIVAXhyKBVqloyLnT9v7"
client_secret = "wZyet4gzXC"
headers ={
"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret
}
def sm(*args):
headers ={
"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret
}
url ="https://openapi.naver.com/v1/search/local.json"
params ={
"query":"서울 맛집",
"display": 3
}
res = requests.get(url,params=params,headers=headers)
data = res.json()
if res.status_code == 200:
print(data)
else:
res.status_code != 200
print(data)
result = 'None'
return data
{'lastBuildDate': 'Thu, 18 Aug 2022 14:25:00 +0900', 'total': 3, 'start': 1, 'display': 3, 'items': [{'title': '영일분식', 'link': '', 'category': '분식>종합분식', 'description': '', 'telephone': '', 'address': '서울특별시 영등포구 문래동4가 8-26', 'roadAddress': '서울특별시 영등포구 도림로141가길 34-1', 'mapx': '302044', 'mapy': '546595'}, {'title': '니커버커베이글', 'link': 'https://www.instagram.com/knickerbockerbagel_official/', 'category': '카페,디저트>베이커리', 'description': '', 'telephone': '', 'address': '서울특별시 송파구 송파동 32-1 1층 109~112호', 'roadAddress': '서울특별시 송파구 석촌호수로 268 1층 109~112호', 'mapx': '321134', 'mapy': '545678'}, {'title': '명동교자 본점', 'link': 'http://www.mdkj.co.kr/', 'category': '한식>칼국수,만두', 'description': '', 'telephone': '', 'address': '서울특별시 중구 명동2가 25-2', 'roadAddress': '서울특별시 중구 명동10길 29', 'mapx': '310579', 'mapy': '551631'}]}
{'lastBuildDate': 'Thu, 18 Aug 2022 14:25:00 +0900',
'total': 3,
'start': 1,
'display': 3,
'items': [{'title': '영일분식',
'link': '',
'category': '분식>종합분식',
'description': '',
'telephone': '',
'address': '서울특별시 영등포구 문래동4가 8-26',
'roadAddress': '서울특별시 영등포구 도림로141가길 34-1',
'mapx': '302044',
'mapy': '546595'},
{'title': '니커버커베이글',
'link': 'https://www.instagram.com/knickerbockerbagel_official/',
'category': '카페,디저트>베이커리',
'description': '',
'telephone': '',
'address': '서울특별시 송파구 송파동 32-1 1층 109~112호',
'roadAddress': '서울특별시 송파구 석촌호수로 268 1층 109~112호',
'mapx': '321134',
'mapy': '545678'},
{'title': '명동교자 본점',
'link': 'http://www.mdkj.co.kr/',
'category': '한식>칼국수,만두',
'description': '',
'telephone': '',
'address': '서울특별시 중구 명동2가 25-2',
'roadAddress': '서울특별시 중구 명동10길 29',
'mapx': '310579',
'mapy': '551631'}]}pd.DataFrame(data["items"])
headers ={
"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret
}
url ="https://openapi.naver.com/v1/search/blog.json"
params = {
"query":"대흉근"
}
res = requests.get(url,headers=headers,params=params)
if res.status_code == 200:
data = res.json()
else:
print("none")
import pprint as pp
pp.pprint(data)
import pandas as pd
pd.DataFrame(data["items"])
def naver(*args):
headers = {
"X-Naver-Client-Id": client_id,
"X-Naver-Client-Secret": client_id
}
url ="https://openapi.naver.com/v1/search/cafearticle.json"
params = {
"query": "개발자",
"display" : 2
}
res = requests.get(url,headers=headers,params=params)
data = res.json()
if res.status_code == 200:
print(data)
else:
print("없음")
return data
pd.DataFrame(data["items"])
파파고 번역 해보기
url ="https://openapi.naver.com/v1/papago/n2mt"
headers ={
"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret
}
data ={
"source":"ko", # 원본언어 코드
"target":"en", # 목적언어 코드
"text": "파이썬은 재밌다." # 번역할 텍스트
}
res = requests.post(url,headers=headers,data=data)
result = res.json()
pp.pprint(result)
{'message': {'@service': 'naverservice.nmt.proxy',
'@type': 'response',
'@version': '1.0.0',
'result': {'dict': None,
'engineType': 'N2MT',
'pivot': None,
'srcLangType': 'ko',
'tarDict': None,
'tarLangType': 'en',
'translatedText': 'Python is fun.'}}}
result["message"]["result"]["translatedText"]
def translate(text,url,client_id,client_secret,source="ko",target="en"):
headers ={
"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret
}
data ={
"source": source, # 원본언어 코드
"target": target, # 목적언어 코드
"text": text # 번역할 텍스트
}
res = requests.post(url,headers=headers,data=data)
result = res.json()
if res.status_code ==200:
result = result["message"]["result"]["translatedText"]
return result
url ="https://openapi.naver.com/v1/papago/n2mt"
text = "이누야샤."
translate(text,url,client_id,client_secret,target="ja")
!pip install git+https://github.com/kmu-agent/api_project.git
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting git+https://github.com/kmu-agent/api_project.git
Cloning https://github.com/kmu-agent/api_project.git to /tmp/pip-req-build-6p98hml1
Running command git clone -q https://github.com/kmu-agent/api_project.git /tmp/pip-req-build-6p98hml1
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from myapi==0.0.1) (2.23.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->myapi==0.0.1) (1.24.3)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->myapi==0.0.1) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->myapi==0.0.1) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->myapi==0.0.1) (2022.6.15)
Building wheels for collected packages: myapi
Building wheel for myapi (setup.py) ... done
Created wheel for myapi: filename=myapi-0.0.1-py3-none-any.whl size=1755 sha256=432177cccfc4502a219c2e5f8ea6f9d864ec8436acbdfd22586d0b6a63ba12a3
Stored in directory: /tmp/pip-ephem-wheel-cache-l1jyt6mj/wheels/31/51/b7/cc95a06356dbc825713521cea5044b80fcc2ce882f287a116b
Successfully built myapi
Installing collected packages: myapi
Successfully installed myapi-0.0.1
from my_api import naver_api
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
import yaml
KEY_FILE = "/content/drive/MyDrive/data/local.yml"
with open(KEY_FILE,"r",) as f:
naver_keys = yaml.load(f)
naver_keys
{'CRIENT_id': 'kIVAXhyKBVqloyLnT9v7', 'CLIENT_SECERET': 'wZyet4gzXC'}import pprint as pp
def search_api(url,client_id,client_secret,params):
headers = {
"X-Naver-Client-Id" : client_id,
"X-Naver-Client-Secret" : client_secret
}
res = requests.get(url,params=params,headers=headers)
result = res.json()
if res.status_code != 200:
print(result)
result = None
return result
if __name__ == "__main__":
CRIENT_id = naver_keys["CRIENT_id"]
CLIENT_SECERET = naver_keys["CLIENT_SECERET"]
url = "https://openapi.naver.com/v1/search/image"
params = {
"query":"아이유"
}
result = naver_api.search_api(url,CRIENT_id,CLIENT_SECERET,params)
pp.pprint(result)
{'display': 10,
'items': [{'link': 'https://i.pinimg.com/736x/da/d5/f3/dad5f3b5dcd1b61abfa8497d5fd7112d.jpg',
'sizeheight': '736',
'sizewidth': '736',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://i.pinimg.com/736x/da/d5/f3/dad5f3b5dcd1b61abfa8497d5fd7112d.jpg&type=b150',
'title': 'Pin page Pin by Yuki Ek on IU아이유 in 2022'},
{'link': 'http://imgnews.naver.net/image/469/2022/06/08/0000679403_001_20220608182004399.jpg',
'sizeheight': '576',
'sizewidth': '640',
'thumbnail': 'https://search.pstatic.net/common/?src=http://imgnews.naver.net/image/469/2022/06/08/0000679403_001_20220608182004399.jpg&type=b150',
'title': ''브로커' 아이유 "언니 출산 이야기, 미혼모 연기에 참고" (인터뷰)'},
{'link': 'https://i.pinimg.com/736x/b4/b4/d6/b4b4d6ca2767aa0b4c7c252afb435455.jpg',
'sizeheight': '981',
'sizewidth': '736',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://i.pinimg.com/736x/b4/b4/d6/b4b4d6ca2767aa0b4c7c252afb435455.jpg&type=b150',
'title': 'Pin by Finey Lee on IU (아이유) in 2022 | Girl, J.i., '
'Cannes'},
{'link': 'http://imgnews.naver.net/image/5129/2022/08/06/1659745067_1648954_20220806092201469.jpg',
'sizeheight': '905',
'sizewidth': '658',
'thumbnail': 'https://search.pstatic.net/common/?src=http://imgnews.naver.net/image/5129/2022/08/06/1659745067_1648954_20220806092201469.jpg&type=b150',
'title': '아이유 측 “콘서트 부정 티켓, 팬클럽 영구제명” [공식입장]'},
{'link': 'https://img.theqoo.net/img/pKiij.gif',
'sizeheight': '370',
'sizewidth': '500',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://img.theqoo.net/img/pKiij.gif&type=b150',
'title': '프로듀사에서 신디 존예라고 왜 아무도 말 안해줬어.gif - 드영배 카테고리'},
{'link': 'https://img.theqoo.net/img/lZLCq.jpg',
'sizeheight': '642',
'sizewidth': '1200',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://img.theqoo.net/img/lZLCq.jpg&type=b150',
'title': '헤메코 개열일 하는 첫주차 호텔 델루나 아이유 의상 모음 - 스퀘어 카테고리'},
{'link': 'https://i.pinimg.com/736x/d0/93/be/d093be8378fc85b5fe0a8b3d281e9b8d.jpg',
'sizeheight': '728',
'sizewidth': '735',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://i.pinimg.com/736x/d0/93/be/d093be8378fc85b5fe0a8b3d281e9b8d.jpg&type=b150',
'title': 'Pin by Yuki Ek on IU아이유 | Iu hair, Korean actresses, '
'Girl model'},
{'link': 'https://i.pinimg.com/736x/56/56/76/5656765b611b3a49430e3c427e3df7b5.jpg',
'sizeheight': '736',
'sizewidth': '736',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://i.pinimg.com/736x/56/56/76/5656765b611b3a49430e3c427e3df7b5.jpg&type=b150',
'title': 'IU Pin by 𝙴𝚖𝚖ã <3 ⁷⟬⟭💜 on IU{아이유} | Alone girl, Bts '
'korea, Korea'},
{'link': 'https://fimg5.pann.com/new/download.jsp?FileID=64440855',
'sizeheight': '783',
'sizewidth': '738',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://fimg5.pann.com/new/download.jsp?FileID=64440855&type=b150',
'title': '아이유도 수해 1억 기부함 : 네이트판 아이유도 수해 1억 기부함'},
{'link': 'https://i.pinimg.com/originals/f7/00/37/f70037f4993e190cfbecdc587274dac9.jpg',
'sizeheight': '990',
'sizewidth': '990',
'thumbnail': 'https://search.pstatic.net/sunny/?src=https://i.pinimg.com/originals/f7/00/37/f70037f4993e190cfbecdc587274dac9.jpg&type=b150',
'title': '아이유★IU 아이유★IU in 2022 | Crown jewelry, Crown, Fashion'}],
'lastBuildDate': 'Fri, 19 Aug 2022 15:44:21 +0900',
'start': 1,
'total': 653575}
rss
!pip install feedparser
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting feedparser
Downloading feedparser-6.0.10-py3-none-any.whl (81 kB)
|████████████████████████████████| 81 kB 3.5 MB/s
Collecting sgmllib3k
Downloading sgmllib3k-1.0.0.tar.gz (5.8 kB)
Building wheels for collected packages: sgmllib3k
Building wheel for sgmllib3k (setup.py) ... done
Created wheel for sgmllib3k: filename=sgmllib3k-1.0.0-py3-none-any.whl size=6066 sha256=54fb9a5a945c92692fe80548c4db233cb6ef1a0d4ee3bbd046fdce160432133f
Stored in directory: /root/.cache/pip/wheels/83/63/2f/117884c3b19d46b64d3d61690333aa80c88dc14050e269c546
Successfully built sgmllib3k
Installing collected packages: sgmllib3k, feedparser
Successfully installed feedparser-6.0.10 sgmllib3k-1.0.0
!pip install goose3
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting goose3
Downloading goose3-3.1.12-py3-none-any.whl (88 kB)
|████████████████████████████████| 88 kB 3.3 MB/s
Requirement already satisfied: lxml in /usr/local/lib/python3.8/dist-packages (from goose3) (4.9.2)
Requirement already satisfied: beautifulsoup4 in /usr/local/lib/python3.8/dist-packages (from goose3) (4.6.3)
Requirement already satisfied: Pillow in /usr/local/lib/python3.8/dist-packages (from goose3) (7.1.2)
Requirement already satisfied: requests in /usr/local/lib/python3.8/dist-packages (from goose3) (2.23.0)
Requirement already satisfied: python-dateutil in /usr/local/lib/python3.8/dist-packages (from goose3) (2.8.2)
Collecting pyahocorasick
Downloading pyahocorasick-1.4.4-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (110 kB)
|████████████████████████████████| 110 kB 9.1 MB/s
Collecting langdetect
Downloading langdetect-1.0.9.tar.gz (981 kB)
|████████████████████████████████| 981 kB 68.2 MB/s
Collecting cssselect
Downloading cssselect-1.2.0-py2.py3-none-any.whl (18 kB)
Requirement already satisfied: six in /usr/local/lib/python3.8/dist-packages (from langdetect->goose3) (1.15.0)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.8/dist-packages (from requests->goose3) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.8/dist-packages (from requests->goose3) (2022.12.7)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.8/dist-packages (from requests->goose3) (2.10)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.8/dist-packages (from requests->goose3) (1.24.3)
Building wheels for collected packages: langdetect
Building wheel for langdetect (setup.py) ... done
Created wheel for langdetect: filename=langdetect-1.0.9-py3-none-any.whl size=993242 sha256=433a7ce70b52d043b39b1d7301f0eeb19f565f3795b15c3dcf132c9491baf478
Stored in directory: /root/.cache/pip/wheels/13/c7/b0/79f66658626032e78fc1a83103690ef6797d551cb22e56e734
Successfully built langdetect
Installing collected packages: pyahocorasick, langdetect, cssselect, goose3
Successfully installed cssselect-1.2.0 goose3-3.1.12 langdetect-1.0.9 pyahocorasick-1.4.4
import pandas as pd
import feedparser
import requests
from goose3 import Goose
from goose3.text import StopWordsKorean
url = 'https://news.google.com/rss/search?q=%EB%B0%98%EB%A0%A4%EB%8F%99%EB%AC%BC&hl=ko&gl=KR&ceid=KR%3Ako'
def get_data(url):
try:
res = requests.get(url)
html = res.text
data = feedparser.parse(html)
print(data.feed.title)
return data
except:
return Noneparsed_data = get_data(url)
type(parsed_data)"반려동물" - Google 뉴스
feedparser.util.FeedParserDictlen(parsed_data['entries']) # 기사 갯수100- 기사 정보확인
num_entries =2
article = parsed_data['entries'][num_entries]
type(article)feedparser.util.FeedParserDict반응형
'python' 카테고리의 다른 글
| [pypthon]파이썬 - pandas 를 이용한 eda (0) | 2023.02.02 |
|---|---|
| [python]파이썬 - pandas (0) | 2023.01.31 |
| [python]파이썬 - pip와 가상환경 (0) | 2023.01.26 |
| [python]파이썬 - 파일 입출력 (0) | 2023.01.26 |
| [python]파이썬 - 정규표현식 (0) | 2023.01.26 |




댓글